前言
- 这里我就是简单讲解一下,计算机的基础,内容没有像网上那样复杂详细,主要目的是快速上手。
- 如果你将来要从事计算机行业,还是最好买本书或者系统课程,详细过一遍计算机从硬软件的基础。
计算机组成
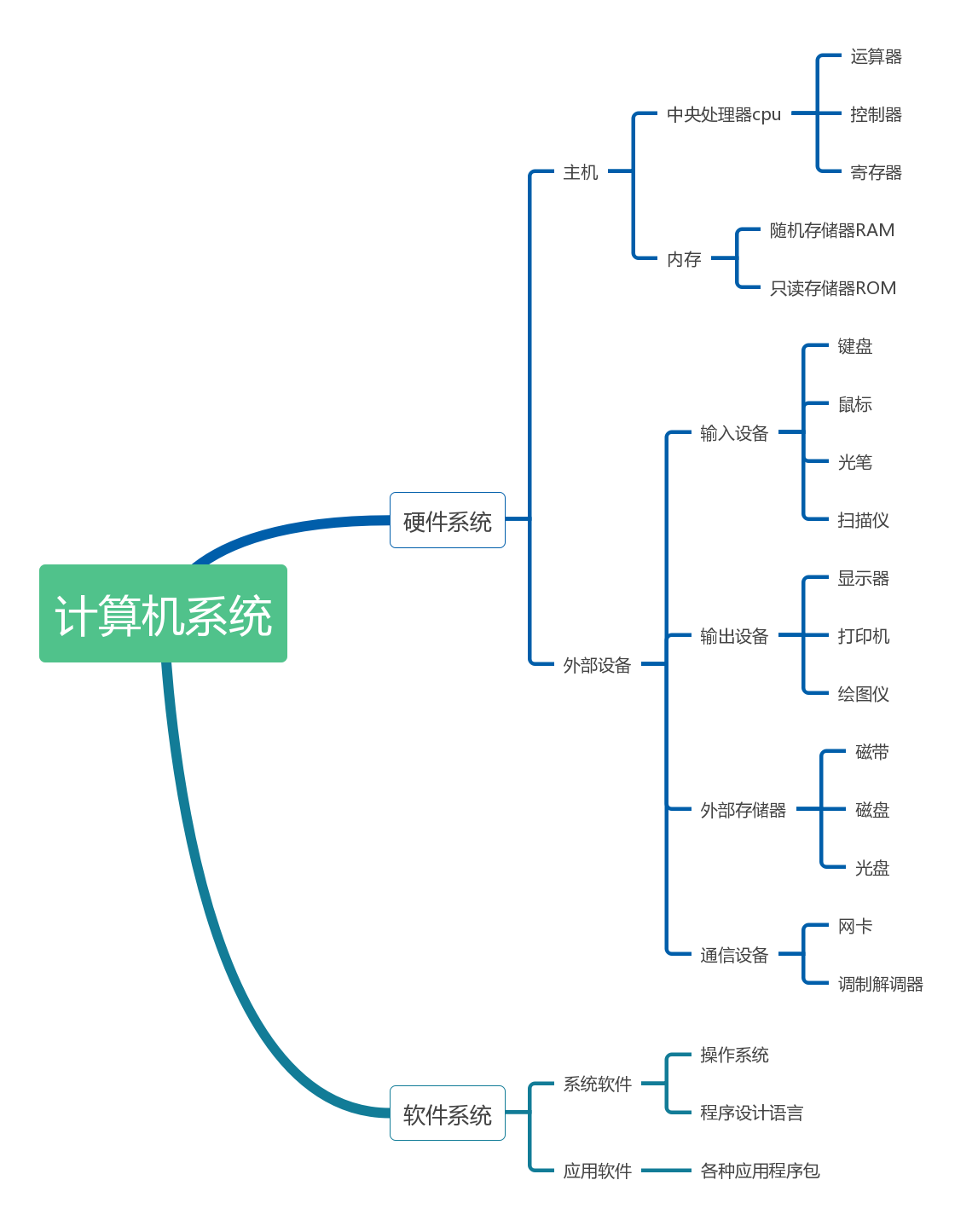
程序运行图
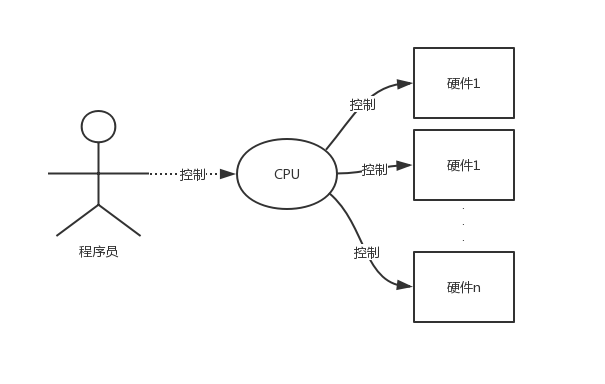
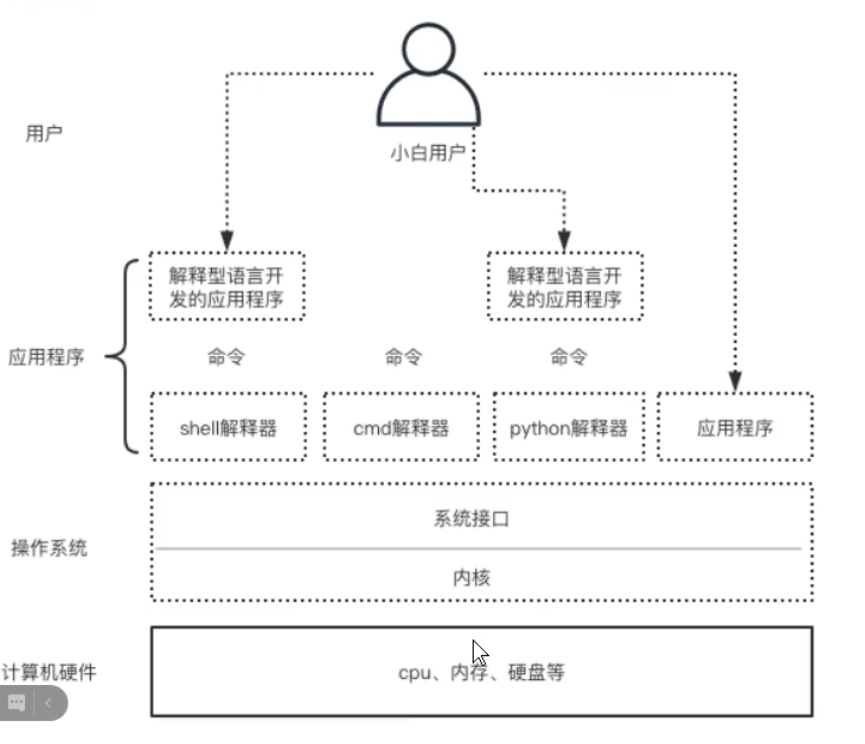
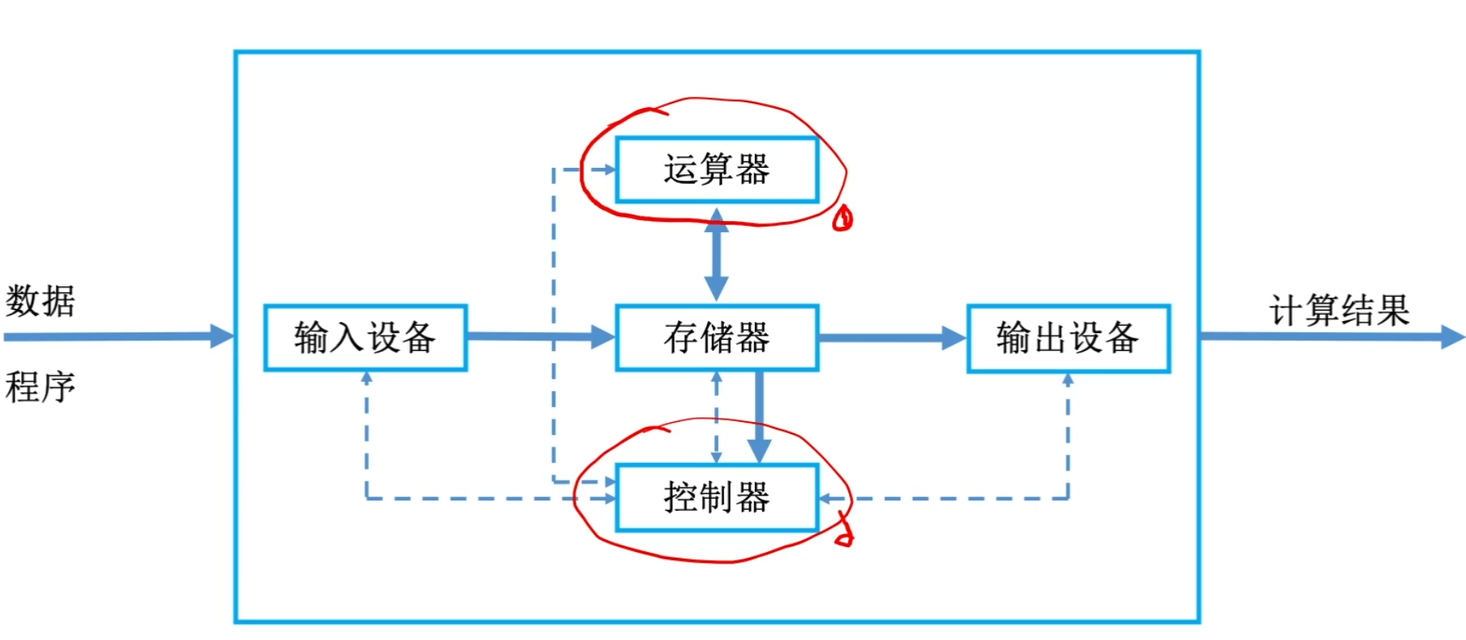
提示
程序的运行,最底层是电压的变化
编程语言
编程语言的两大类区别
分类:
编译型语言:c语言、c++、go语言等
解释性语言:python、JavaScript、php等区别:
- 编译型:先全部翻译成机器码,再执行。
优点:生成了可直接运行的机器码,因此运行效率较高。
缺点:开发繁琐,同一个软件,需要开发多套,进行适配不同的操作系统。 - 解释性:翻译一句,执行一句。
优点:易开发,可以在不同操作系统运行,语法简明,易掌握。
缺点:每次运行时都需要逐行或逐块翻译源代码,运行效率慢。
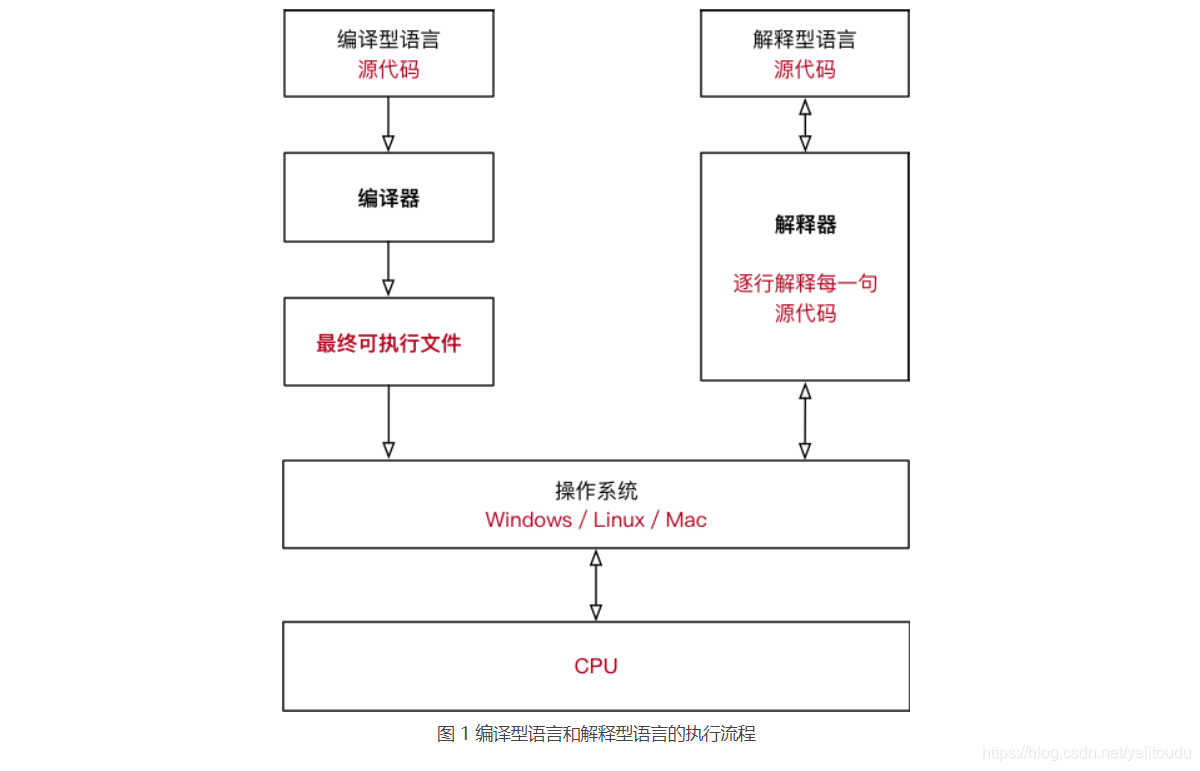
认识键盘

- 这里简单说明一下控制键区域
| PrtScSysRq | ScfollLock | PauseBreak | Insert | Home | PageUp | Delete | End | PageDown |
|---|---|---|---|---|---|---|---|---|
| 截图 | 滚轮锁定 | 暂停程序 | 插入和改写切换 | 光标移动一行的开头 | 上一页 | 删除 | 光标移动一行的结尾 | 下一页 |
键盘上的冷知识
- `是反引号,在键盘左上部分,在esc键下面,数字1的左边
- tab键 可以理解为4个空格,严格来说他是制表键
- CapSLk键 大写
- win键是在最下面一行由4个小方块组成。
- win+
.特殊符号选择
如何打字


推荐打字软件
- 金山打字通:https://www.51dzt.com/
上面这些图来源于金山打字通,里面有更详细的新手教程,非常推荐新手小白上手。
- 推荐网站:
- https://www.typingclub.com/ (打字俱乐部)
- https://qwerty.kaiyi.cool/ (qwerty)
- https://daziya.com/ (打字鸭)
- 推荐chrome浏览器打开。官网地址:https://google.cn/chrome/
打字冷知识
shift+数字=符号 。例如shift+6=省略号……shift+字母=大写- 在打中文时候,按下键盘上一排的数字,可以选择指定文字。按空格默认选择第一个。
- 按下
'可以进行分词操作。比如“西安”,xi'an。而不是xian “先”
这个分词键'在回车键的左边 - 如果打中文,输入法一行找不到需要的字,需要继续往下一页找,只需按下
<或>就可以实现一行的上下切换。 - 全角和半角 切换快捷键:
shift+空格
区别:
全角模式:输入一个字符占用2个字符
半角模式:输入一个字符占用1个字符
列子:全角:,半角,
忠告
- 先练习英文,坚持每天一篇文章,不要太多
- 重要的不是一天能练习多少量,而是尽可能能坚持每天打字
快捷键
编程篇
| ctrl+c | ctrl+v | ctrl+a | ctrl+d | ctrl+z | shift+tab | shift+enter | shift+ctrl+↑ |
|---|---|---|---|---|---|---|---|
| 复制 | 粘贴 | 全选 | 复制当前行到下行 | 回到上一步 | 选中多行缩减空格 | 直接定位下一行 | 代码整体上移 |
| ctrl+h | ctrl+s | ctrl+tab | ctrl+w | ctrl+o | ctrl+n | ctrl+f | shift+ctrl+↓ |
| 替换 | 保存 | 切换窗口 | 关闭窗口 | 打开文件 | 新建 | 查找 | 代码整体下移 |
多行同时编辑
- 按住滚轮进行上下选择
Windows篇
| win+q | win+e | win+r | win+i | win+g | win+L | win+d |
|---|---|---|---|---|---|---|
| 查找 | 打开我的电脑 | 运行程序窗口 | 打开设置 | 录屏 | 锁屏 | 回桌面 |
| win+v | win+空格 | win++或- | win+↑或 ↓ | alt+tab | alt+f4 | ctrl+数字 |
| 剪切板 | 切换输入法 | 调用放大镜查看 | 放大缩小窗口 | 切换程序 | 关闭程序 | 精准切换窗口 |
| win+m | win+shift+m | win+shift+s | esc+shift+ctrl | win+x | ctrl+shift | f11 |
| 最小化所有窗口 | 还原最小化窗口 | 截图 | 资源管理器 | 常用小功能 | 切换输入法 | 窗口充满全屏 |
终端cmd和powershell
黑白窗口
- 你可能会看到下面这种黑白窗口,其实,他就是启动一些程序的一个窗口,需要敲一些命令才能打开某些程序。
只不过现在,操作系统给我们提供一个可视化的桌面。我们只需要点点鼠标就可以,打开某个软件。
区别
- cmd 内存占用少,只能运行少量程序,执行一些简单的脚本
- powershell 内存占用较大,cmd能运行的,他都能行,可以运行复杂脚本
计算机编码详解
计算机编码详解
计算机编码是计算机系统中用于表示和处理信息(如文字、数字、符号等)的规则和方法。由于计算机底层只能识别二进制(0和1),编码的核心作用就是建立"人类可理解的符号"与"二进制数"之间的对应关系。下面从基础概念、常见编码类型、发展历程及应用场景等方面详细讲解:
一、编码的核心原理
- 本质:将字符(如字母、汉字、标点)映射为二进制数(比特流),以便计算机存储、传输和处理。
- 关键要素:
- 字符集:定义编码所包含的字符范围(如英文字母、汉字、特殊符号)。
- 映射规则:字符与二进制数的对应关系(如字母"A"对应
01000001)。 - 编码长度:每个字符对应的二进制位数(如ASCII码用1字节,UTF-8用1-4字节)。
二、常见编码类型及特点
1. ASCII码(American Standard Code for Information Interchange)
- 背景:1963年诞生,最早的通用编码,针对英语设计。
- 字符集:包含128个字符,分为:
- 可打印字符(95个):英文字母(大小写)、数字(0-9)、标点符号(如
!、,)、空格等。 - 控制字符(33个):不可显示,用于控制设备(如换行
\n、回车\r、退格\b)。
- 可打印字符(95个):英文字母(大小写)、数字(0-9)、标点符号(如
- 编码规则:用1字节(8位)表示,但最高位固定为0(实际用7位),范围是
00000000(0)到01111111(127)。- 示例:
A→01000001(十进制65),a→01100001(十进制97),0→00110000(十进制48)。
- 示例:
- 局限:仅支持英语,无法表示其他语言(如中文、俄语、阿拉伯语)。
2. 扩展ASCII码
- 背景:为解决ASCII码字符不足的问题,部分地区对8位中的最高位(第8位)进行利用。
- 字符集:共256个字符(
00000000到11111111),新增128个字符,包括:- 欧洲语言字符(如法语的
é、德语的ü)、特殊符号(如货币符号€、£)。
- 欧洲语言字符(如法语的
- 问题:无统一标准,不同地区定义不同(如IBM扩展ASCII与微软扩展ASCII冲突),导致跨系统兼容性差。
3. GB系列编码(中文编码)
- 背景:针对中文设计,解决ASCII码无法表示汉字的问题。
- 主要类型:
GB2312(1980年):
- 字符集:包含6763个简体汉字、682个非汉字符号(如日文假名、希腊字母)。
- 编码规则:用2字节表示,每个字节的最高位为1(区别于ASCII码),范围是
00100001-01111110(第一字节)和00100001-11111110(第二字节)。 - 局限:不包含生僻字和繁体汉字。
GBK(1995年):
- 兼容GB2312,扩展了字符集(共21003个汉字,包括繁体、生僻字)。
- 编码规则:仍用2字节,但取消了GB2312对字节范围的限制,覆盖更多字符。
GB18030(2000年):
- 目前中文国家标准编码,兼容GB2312和GBK,支持所有汉字(包括少数民族文字)。
- 编码规则:采用变长编码(1字节、2字节或4字节),1字节兼容ASCII,2字节兼容GBK,4字节用于补充罕见字符。
4. Unicode(统一码/万国码)
- 背景:20世纪90年代,为解决"编码碎片化"(如中文用GBK、日文用Shift-JIS)的问题,国际组织推出的统一字符集。
- 核心目标:为世界上所有字符(包括文字、符号、 emoji)分配唯一的二进制编号(称为"码点",格式为
U+XXXX)。 - 字符集规模:目前包含超过14万个字符,覆盖几乎所有语言(如中文、梵文、古埃及象形文字)和符号(如
©、😊)。- 示例:
A→U+0041,中→U+4E2D,😊→U+1F60A。
- 示例:
- 注意:Unicode仅定义"字符→码点"的映射,不直接规定二进制存储方式,具体存储需通过UTF(Unicode Transformation Format)实现。
5. UTF编码(Unicode的实现方式)
UTF是将Unicode码点转换为二进制字节流的编码方式,常见类型有:
| 编码类型 | 特点 | 适用场景 |
|---|---|---|
| UTF-8 | 变长编码:1-4字节表示一个字符 - 兼容ASCII(单字节字符与ASCII完全一致) - 多字节字符的首字节以 110(2字节)、1110(3字节)等开头,后续字节以10开头示例: 中(U+4E2D)→11100100 10111000 10100101(3字节) | 网络传输(如HTTP)、文件存储(跨平台兼容性最佳)、网页(HTML默认) |
| UTF-16 | 固定2字节或4字节 - 大部分常用字符(如中文、英文)用2字节 - 罕见字符(如emoji)用4字节(通过代理对实现) 分大端(UTF-16BE)和小端(UTF-16LE)存储 | Windows系统(内核默认)、Java/C#字符串存储 |
| UTF-32 | 固定4字节表示一个字符,直接对应Unicode码点 示例: 中→00004E2D(十六进制) | 需快速索引字符的场景(如文本编辑器),但存储效率低 |
三、编码发展的核心矛盾与解决
矛盾1:字符覆盖范围 vs 存储效率
- 早期编码(如ASCII)效率高(1字节),但覆盖范围窄;
- 现代编码(如UTF-8)通过变长设计平衡:常用字符(英文)用1字节,生僻字符用多字节。
矛盾2:地区差异 vs 兼容性
- 各国曾推出本地化编码(如中国GBK、日本Shift-JIS),导致"乱码"(用A编码存储的文件,用B编码打开);
- Unicode+UTF-8的普及解决了这一问题,成为跨语言、跨平台的通用标准。
四、常见问题:乱码的产生与解决
- 乱码原因:编码与解码使用的规则不一致(如用GBK编码的文件,用UTF-8打开)。
- 示例:用GBK编码的"中"字(二进制
11010110 11000001),若用UTF-8解码,会被误判为两个无效字符,显示为�或乱码符号。 - 解决方法:确保文件存储、传输、打开时使用统一编码(推荐UTF-8)。
五、总结
计算机编码的发展是从"局部适用"到"全球统一"的过程:
- ASCII→解决英语需求;
- 扩展编码→适配地区语言;
- Unicode+UTF→实现全球字符统一表示。
- utf是unicode编码的实现
如今,UTF-8凭借兼容性和效率成为主流,广泛应用于互联网、操作系统和软件开发中。理解编码规则有助于解决文件乱码、数据传输错误等实际问题。